【応用情報技術者】データベースの用語メモ
ACID特性
ACID(Atomicity、Consistency、Isolation、Durability)は、データベーストランザクションの信頼性と一貫性を確保するための特性の頭文字を表す言葉です。データベース管理システム(DBMS)において、ACID特性は非常に重要で、データの信頼性と整合性を保つために使用されます。以下は、ACID特性の詳細です:
-
Atomicity(原子性):
- トランザクションは、すべての操作が完了するか、すべてが失敗するかのどちらか一方の状態になる必要があります。トランザクション内の操作は、すべて成功するか、すべて失敗するかのいずれかで、途中で途切れたり中断されたりしないことを保証します。原子性は、トランザクションの中途でエラーが発生した場合、変更をロールバックしてデータベースを元の状態に戻すために使用されます。
- トランザクション内の処理は,全てが実行されるか,全てが取り消されるかのいずれかである。
-
Consistency(一貫性):
- トランザクションが実行される前後で、データベースは一貫性を保つ必要があります。つまり、トランザクションの前後でデータベースの整合性規則が依然として適用され、データベースが無効な状態にならないようにすることが求められます。
-
Isolation(隔離性):
- 複数のトランザクションが同時に実行されている場合でも、各トランザクションは互いに影響を及ぼさず、それぞれ独立して実行されているかのように見える必要があります。隔離性は、トランザクション同士の干渉や競合を防ぎ、データベースの整合性を保つのに役立ちます。
-
Durability(耐久性):
- トランザクションが成功的に完了した場合、その変更は永続的であり、データベースが障害やシステムの再起動などに対して耐性を持つ必要があります。耐久性は、データの喪失や破損を防ぎ、信頼性を高めるのに役立ちます。
- 正常に終了したトランザクションの更新結果は,障害が発生してもデータベースから消失しないこと
ACID特性は、トランザクション処理の信頼性を確保し、データベースが整合性を保つための基本的な要素です。
ANSI/SPARC 3層スキーマ
ANSI/SPARCモデル(またはANSI/SPARC 3層スキーマ)は、データベースの設計と管理に関する基本的な概念とモデルを提供するために開発されたデータベース管理システム(DBMS)の設計アーキテクチャに関するモデルです。このモデルは、1975年に米国国家規格協会(ANSI)と米国情報プロセッシング協会(Information Processing Association of America、後のACM SIGMOD)とSPARC(Standard Planning and Requirements Committee)によって提唱されました。
ANSI/SPARC 3層スキーマモデルにおける内部スキーマの設計に含まれるもの
- SQL問合せ応答時間の向上を目的としたインデックスの定義
B+木インデックス
B+木インデックス(B+ Tree Index)は、データベース管理システムやファイルシステムなどで効率的なデータ検索を支援するために使用されるデータ構造です。B+木は、主にデータベーステーブルの索引やファイルの索引など、大容量のデータを高速に検索するために設計されています。
木の深さが一定で、節点はキー値と子部分木へのポインタをもち、葉のみが値をもつ平衡木(バランス木)を用いたインデックス法です
h=logbX
CAP定理
CAP定理(CAP Theorem)は、分散コンピューティングおよびデータベース設計に関連する基本的な原則の一つです。この定理は、分散システムが3つの主要な性質である「一貫性(Consistency)」、「可用性(Availability)」、「分割耐性(Partition Tolerance)」のうち、最大2つしか満たせないということを示します。
- 可用性と分断耐性を満たすが整合性を満たさない。
CASCADE
“CASCADE”は、SQL(Structured Query Language)コマンドおよびデータベース操作に関連する用語で、特定の操作が関連するデータに影響を及ぼす方法を指定するために使用されます。CASCADEは、データベース内のテーブル間やリレーションシップ間で操作が連鎖的に影響することを示します。
CURSOR
カーソル操作は、アプリケーションプログラムからデータベースへの問合せによって得られた導出表を、表データを直接扱えない手続き型プログラム言語に1行ずつ渡す機能を提供するものです。SQLではカーソル宣言に”DECLARE CURSOR”、カーソル位置のデータ取得および次データへの移動に”FETCH”文を使います。
DISTINCT
SQL(Structured Query Language)のDISTINCTキーワードは、データベースから取得した結果セットから重複を削除するために使用されます。DISTINCTを使用すると、クエリの結果セットにおいて一意の値のみを返すことができます。これは主にSELECT文と組み合わせて使用され、重複した値を除外してデータを取得したい場合に便利です。
E-Rモデル
E-Rモデル(Entity-Relationship Model)は、データベース設計とデータモデリングのための概念的なモデルです。E-Rモデルは、実体(エンティティ)、関係(リレーションシップ)、属性(属性)などを用いて、データの構造や関連性を視覚的に表現するためのツールです。E-Rモデルは、データベースの設計とデータモデリングに広く使用され、データベースの設計、開発、管理プロセスにおいて非常に重要です。
データベースの概念設計に用いられ,対象世界を,実体と実体間の関連という二つの概念で表現するデータモデル
ETL
データウェアハウスに業務データを取り込むとき,データを抽出して加工し,データベースに書き出すツール
ETLは、Extract,Transform,Loadというデータウェアハウス構築における3つの工程の頭文字を合わせた言葉です。
- Extract(抽出)
- 企業内に存在する複数のシステムからデータを抽出し、それぞれの異なるデータフォーマットを次の加工工程に適した同一のデータフォーマットに変換する。
- Transform(変換・加工)
- 抽出した生データにデータ形式の統一、欠損値の補完、単位の統一、異常値の処理などを行い、データの書き出しができる状態にする。(データクレンジング)
- Load(ロード・書き出し)
- データウェアハウスなどの出力先に書き出す。
GRANT文
特定のユーザに表などのオブジェクトに関する権限を付与するSQL文
JSON(JavaScript Object Notation)
JSON(JavaScript Object Notation)は、データの交換や保存に使用される軽量なデータフォーマットです。JSONは、テキストベースの形式で、人間が読み書きしやすく、多くのプログラミング言語でサポートされています。JSONは、オブジェクトと配列を含む、シンプルなデータ構造を表現するために使用されます。
- ドキュメントデータベースを使用し,項目構成の違いを区別せず,商品データ単位にデータを格納する。
NoSQL
NoSQL(ノンSQLまたは”Not Only SQL”の略)は、リレーショナルデータベースシステム(RDBMS)に代わるデータベースアプローチの一つで、非構造化データ、半構造化データ、大規模なデータセット、高いスケーラビリティ要件など、伝統的なリレーショナルデータベースシステムが苦手とするデータを効果的に格納および操作するために設計されました。
- 様々な形式のデータを一つのキーに対応付けて管理するキーバリュー型データベース
UNIQUE制約
UNIQUE制約は、リレーショナルデータベース内のテーブルに適用されるデータ整合性の制約(条件)の一つです。UNIQUE制約は、特定の列または列の組み合わせに一意性を強制するために使用されます。つまり、同じ値がその列(または列の組み合わせ)に複数回現れないようにします。UNIQUE制約が適用された列は、ユニークキーとも呼ばれます。
UNION ALL
和集合演算を行う演算子で、複数のSELECT文の結果セットを1つに統合する機能を持ちます。通常のUNIONでは、2つの結果セットに全く同じレコードがあった場合に重複行が削除された結果を返しますが、UNION ALLでは重複行を含めた結果を返します。
undo/redo方式
「undo/redo方式」は、コンピュータプログラムやソフトウェアアプリケーションにおいて、ユーザーが行った操作を取り消す(undo)または再実行する(redo)機能の実装方法を指します。
インデックス(index)
インデックス(index)は、索引(さくいん)とも呼ばれデータベースへのアクセス効率を向上させるために、検索対象となるデータ項目に対してインデックス・テーブルと呼ぶテーブルを作成し、それを使ってレコードを検索します。
- インデックスの設定に際しては,検索条件の検討だけでなく,テーブルのレコード数についての考慮も必要である。
オブジェクト指向データベース
オブジェクト指向データベース(Object-Oriented Database, OODB)は、データベース管理システム(DBMS)の一種で、データベース内のデータをオブジェクト指向プログラミングの概念に基づいて格納、管理、操作するために設計されたデータベースシステムです。これは、伝統的なリレーショナルデータベース(RDBMS)とは異なるアプローチを取ります。
- データと手続がカプセル化され一体として扱われるので,構造的に複雑で,動作を含む対象を扱うことができる。
オプティマイザ(optimizer)
オプティマイザ(optimizer)は、SQL文が実行された際、対象となるレコードの取得時間を最小とするようにアクセスパスを最適化するデータベース管理システム(DBMS)の機能です。レコードを取得するためには、インデックスの使用や表全体の読込みなどの複数の方法が考えられます。オプティマイザはクエリの実行計画を評価し、問合せ内容に応じて最も効率がよい方法を選択します。
コストベースのオプティマイザがSQLの実行計画を作成する際に必要なもの
- 統計情報
外部スキーマ
外部スキーマ(External Schema)は、データベース管理システム(DBMS)のANSI/SPARCモデルにおいて、データベースにアクセスするユーザーやアプリケーションプログラムがデータを見る方法を定義する部分です。外部スキーマは、ユーザーがデータベース内の情報にアクセスするために必要なビュー、テーブル、クエリ、レポートなどのデータの論理的な表現を提供します。
サブスキーマ:外部スキーマの別称。
- 外部スキーマは,データの利用者からの見方を表現する。
概念スキーマ
概念スキーマ(Conceptual Schema)は、データベース管理システム(DBMS)のANSI/SPARCモデルにおいて、データベース内のデータの全体的な構造と関係を定義する部分です。このスキーマは、データベース内のデータを抽象的に表現し、異なる外部スキーマが同じデータベースを共有できるようにするために使用されます。
関数従属性
関数従属性とは、レコードのあるデータ項目が決まれば、他のデータ項目も一意に決まる関係のことです。
グラフ指向DB
グラフ指向データベース(Graph Database)は、データをノード(ノードはエンティティやオブジェクトを表す)とエッジ(エッジはノード間の関係を表す)から成るグラフ構造で表現し、データ間の関連性やパターンを効率的に保存、クエリ、検索するために設計されたデータベースです。これは、複雑なデータの関係を表現する必要があるアプリケーションに適しています。
- ノード,リレーション,プロパティで構成され,ノード間をリレーションでつないで構造化する。ノード及びリレーションはプロパティをもつことができる。
候補キー
候補キーとは、表のある行を一意に特定することができる属性、または属性の組合せで主キーの候補となるキーです。1つの表に複数の候補キーがある場合には、その中で項目の組合せが最小でその表の性質にあったものを主キーとします。
再編成
再編成は、データベース中にレコードの追加や削除によって断片的な未使用領域が増加した場合や、繋がりのあるのレコードが非連続的な領域に格納され、順次アクセスの効率が低下した場合に行われる処理です。
データベースにデータの追加,削除などが多数繰り返されて,データベース全体のアクセス効率が低下したときに,データベースに対して行う処理
参照制約
参照制約(Referential Constraint)は、リレーショナルデータベース内でデータ整合性を確保するための制約(条件)の一つです。参照制約は、異なるテーブル間の関連性を維持し、データの整合性を維持するのに役立ちます。具体的には、参照制約は外部キー(Foreign Key)としても知られ、以下の2つの主要な要素から構成されます:
-
親テーブル(親エンティティ): 参照制約を定義するテーブルのことです。このテーブルは一般的に関連性を示す一意の値(主キーまたは候補キー)を持っています。
-
子テーブル(子エンティティ): 参照制約を適用するテーブルのことです。このテーブルは親テーブルのキー(通常は外部キーとして参照)を持っています
参照制約とは、関係データベースにおける整合性制約の一つで「ある表で参照しようとしている値が、参照先の表で候補キーとして存在しなければならない」というものです。
FOREIGN KEYとREFERENCESを用いて指定する制約
ストアドプロシージャ
ストアドプロシージャ(Stored Procedure)は、データベース内で実行可能なプリコンパイルされたSQLコードのブロックであり、一連のデータベース操作を実行するために使用されるプログラムの一種です。ストアドプロシージャは、データベース内のデータの操作、変換、検証などのタスクを自動化し、アプリケーションからデータベースに対する複数のクエリをまとめて実行できるようにします。
- アプリケーションから一つずつSQL文を送信する必要がなくなる。
- クライアント側のCALL文によって実行される。
- サーバとクライアントの間での通信トラフィックを軽減することができる。
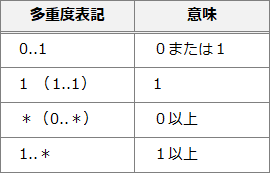
多重度
多重度(Multiplicity)は、データベース設計やモデリングにおいて、関連性のあるエンティティ(データの実体)間の関係を示す際に使用される概念です。多重度は、関連内のエンティティの数や、それらのエンティティ間の関係の性質を記述します。主にリレーショナルデータベースのテーブル間の関係や、オブジェクト指向モデリングにおけるクラス間の関係を定義する際に使用されます。
第1正規形
第1正規形(First Normal Form、1NF)は、データベースデザインにおける基本的な正規形の1つであり、リレーショナルデータベース内のテーブルが特定の条件を満たすことを定義しています。1NFは、データの重複を排除し、データの一貫性を確保するのに役立ちます。以下は、第1正規形に関する詳細な情報です。
第1正規形の条件:
-
値のアトミシティ(Atomicity): テーブル内の各セル(データの単位)は、不可分の単純な値でなければなりません。つまり、セル内には複数の値が含まれていてはいけません。例えば、1つのセルに「John Smith」と「123 Main St.」という名前と住所の組み合わせが含まれているようなデータは1NFを満たしません。
-
一意の列名: 各列(属性)は一意の名前を持ち、異なる属性間で名前の重複が許されません。列名はデータベース内で一意である必要があります。
第1正規形を満たすことによって、データの冗長性を削減し、データの正確性と整合性を向上させることができます。データベース内で1NFを満たすデータは、単純で理解しやすく、クエリやデータ操作が容易になります。また、1NFはデータベースを正規化するプロセスの最初のステップであり、データの不必要な複製を排除するのに役立ちます。
1NFを達成するための具体的なステップは以下の通りです:
- テーブルの各列に一意の名前を付けます。
- 各セルには1つの単純な値が含まれるようにデータを整理します。必要に応じて、複雑なデータの構造を別のテーブルに分割します。
1NFを満たすことは、データベースの設計と正規化の基本的な原則であり、その後の正規形(2NF、3NF、BCNFなど)の達成に向けたステップの出発点となります。
第2正規形
第2正規形(Second Normal Form、2NF)は、データベースデザインにおける正規形の一つであり、リレーショナルデータベース内のテーブルが特定の条件を満たすことを規定しています。2NFの主な目的は、データの冗長性をさらに排除し、データベースの整合性を向上させることです。
第2正規形を理解するためには、まず以下の用語を知っておく必要があります:
-
主キー(Primary Key): テーブル内の各レコード(行)を一意に識別するための列(または列の組み合わせ)です。
-
部分関数従属(Partial Functional Dependency): これは、テーブル内の非キー属性(主キー以外の列)が主キーの一部にだけ依存している状態を指します。つまり、主キーの一部を変更すると、非キー属性の値が変わる可能性があるということです。
第2正規形の条件:
- 全ての非キー属性が主キーに完全に関数従属していること: テーブル内の各非キー属性は、主キーのすべての列(または主キーの候補キーのすべての列)に完全に関数従属していなければなりません。部分関数従属が許容されません。
第2正規形を満たすことによって、データの冗長性を排除し、データベース内のデータの一貫性を向上させることができます。また、テーブルの設計を合理化し、データの整理が容易になります。
第2正規形を達成するためには、以下の手順が必要です:
- テーブルを分析し、主キー(または主キーの候補キー)を識別します。
- 各非キー属性が主キーのすべての列に完全に関数従属しているか確認します。
- 部分関数従属が存在する場合、その非キー属性を別のテーブルに移動し、関連性を確立します。これにより、各テーブルが第2正規形を満たすようになります。
第2正規形は、データベース設計のプロセスで通常第1正規形(1NF)に達した後に適用されます。データベースを正規化するプロセスは、データベースのデータ整合性を向上させ、効率的なデータ操作を可能にするために重要です。
第3正規形
第3正規形(Third Normal Form、3NF)は、データベースデザインにおける正規形の一つであり、リレーショナルデータベース内のテーブルが特定の条件を満たすことを規定しています。3NFの主な目的は、データの冗長性を排除し、データベースの整合性を向上させることです。
第3正規形を理解するためには、以下の用語を知っておく必要があります:
-
主キー(Primary Key): テーブル内の各レコード(行)を一意に識別するための列(または列の組み合わせ)です。
-
候補キー(Candidate Key): 主キーになりうる列(または列の組み合わせ)です。候補キーは主キーと同様に一意性を持ち、主キーが選ばれる前に候補キーとして考えられます。
-
非キー属性(Non-Key Attribute): 主キー以外のテーブル内の属性(列)です。
第3正規形の条件:
- すべての非キー属性が、主キーまたは候補キーに推移的関数従属していること: テーブル内の各非キー属性は、主キーまたは候補キーに直接的または間接的に関数従属している必要があります。つまり、非キー属性は主キーまたは候補キーに対して推移的関数従属していることを示します。
第3正規形を満たすことによって、データの冗長性を排除し、データベース内のデータの一貫性を向上させることができます。また、テーブルの設計をさらに合理化し、データの整理が容易になります。
第3正規形を達成するためには、以下の手順が必要です:
- テーブルを分析し、主キーと候補キーを識別します。
- 各非キー属性が、主キーまたは候補キーに推移的関数従属しているか確認します。
- 推移的関数従属が存在する場合、関連する非キー属性を別のテーブルに移動し、新しいテーブルを作成します。これにより、各テーブルが第3正規形を満たすようになります。
第3正規形は、データベース設計のプロセスで通常第1正規形(1NF)および第2正規形(2NF)に達した後に適用されます。データベースを正規化するプロセスは、データベースのデータ整合性を向上させ、効率的なデータ操作を可能にするために重要です。
- 冗長性が排除され,データの整合性を保ちやすくなる。
- 候補キー以外の属性間に関数従属性がある場合,その関係を分解する。
デッドロック
デッドロックは、共有資源を使用する2つ以上のプロセスが、互いに相手プロセスの必要とする資源を排他的に使用していて、互いのプロセスが相手が使用している資源の解放を待っている状態に陥ってしまうことをいいます。
データマイニング
データマイニング(Data Mining)は、大量のデータから有用な情報やパターンを抽出し、そのデータに隠れた知識を発見するためのプロセスや技術のことを指します。データマイニングは、統計学、人工知能、機械学習、データベースの管理技術など、さまざまな分野の手法を組み合わせています。
- 蓄積されたデータを分析し,単なる検索だけでは分からない隠れた規則や相関関係を見つけ出すこと
データレイク
データレイク(Data Lake)は、大規模なデータを格納し、管理するためのデータストレージアーキテクチャまたはデータ管理アプローチの一つです。データレイクは、構造化データ、非構造化データ、半構造化データなど、さまざまなデータ形式を保存し、後で分析や処理するためにデータを保持することができます。
- 必要に応じて加工するために,データを発生したままの形で格納する。
- あらゆるデータをそのままの形式や構造で格納しておく。
データディクショナリ
データディクショナリ(Data Dictionary)は、データベース管理システム(DBMS)やデータ管理環境において使用される、データに関するメタデータ(データに関するデータ)を記録・管理・文書化するための中央集中的なリソースまたはデータベースです。データディクショナリは、データの定義、説明、関連情報、データの構造、データ項目の属性、データフロー、データベースの設計、データベースオブジェクト(テーブル、ビュー、インデックスなど)に関する情報など、データ管理に関連するさまざまな情報を提供します
- 概念スキーマ、外部スキーマ、内部スキーマとそれらの変換定義情報
- 表、ビュー、インデックス、その他オブジェクトの定義情報
- 参照制約、検査制約の定義情報
- ユーザ情報
- アクセス権と機密保護に関する情報
- 集中管理方式では,データディクショナリ/ディレクトリを保有するサイトの障害が,分散データベースシステムの重大な障害になる。
導出表
導出表は、1つ以上の基礎となる実表(DBに実データを持つ表)から関係演算・集合演算といったSQL問合せによって作成される仮想的な表全般を指します。SELECT文で得られる結果の他にも、GROUP BY句やWITH句を処理する際に内部的に作られる一時的な表も導出表の1つです。ビューは導出表の一つの形態であり、導出表に名前を付けて実表と同じように参照(条件次第では更新も)できるようにしたものです。
- 何らかの問合せによって得られた表である。
内部スキーマ
内部スキーマ(Internal Schema)は、データベース管理システム(DBMS)のANSI/SPARCモデルにおいて、データベースの物理的な実装やデータの格納方法を記述する部分です。内部スキーマは、データベース内のデータが物理メディア上にどのように格納され、管理されるかを定義します。
データベースを記録媒体にどのように格納するかを記述したもの
2相コミットプロトコル
2相コミットプロトコル(Two-Phase Commit Protocol)は、分散データベースシステムや分散トランザクション処理において、複数のデータベースやリソースマネージャ間でトランザクションのコミット(確定)を確実に行うためのプロトコルです。
- 主サイトが全ての従サイトからコミット準備完了メッセージを受け取った場合,全ての従サイトに対してコミット要求を発行する。
ハッシュインデックス
ハッシュインデックスは、ハッシュ関数を基に、格納位置を求める手法です。ハッシュ関数には「異なったキー値でも同一の算出結果が得られてしまう可能性がある」という性質があるので、ハッシュインデックスを用いた場合はキー値の衝突(シノニム)が起こる可能性があります。
べき等(idempotent)な操作
べき等(idempotent)な操作は、同じ操作を何度実行しても結果が変わらないまたは同じ状態になる特性を持つ操作です。つまり、操作を複数回実行しても初回実行と同じ結果が得られ、データやシステムに副作用が生じないことを保証します。べき等性は、分散システムやネットワークプロトコル、データベース、API設計などさまざまなコンピュータ関連の領域で重要です。
- 同一の操作を複数回実行した結果と,一回しか実行しなかった結果が同一になる操作
メタデータ
- データの定義情報を記述したデータ
メタデータは、データについてのデータという意味で、データ本体に付随する情報のことをいいます。
レプリケーション
元のデータベースと同じ内容の複製データベースをあらかじめ用意しておき,元のデータベースの更新に対し,非同期にその内容を複製データベースに反映する手法
レプリケーション(Replication)は、DBMS(データベースマネジメントシステム)が持つ機能の一つで、データベースに加えた変更を他の複製データベースにも自動的に反映させることで信頼性や耐障害性を高める仕組みです。
ロールフォワード
ロールフォワード(前進復帰)は、データベースシステムに障害が起こったとき、トランザクションの更新後ログを使用することで過去に処理したトランザクションを再現し、システム障害の直前までデータベースの状態を回復させる処理です。
ロック
共有ロック
データを読込むときに使うロックで、資源がこの状態の場合は他のトランザクションによる更新処理ができなくなる(読込みは可能)。
専有ロック
データを更新するときに使うロックで、資源がこの状態の場合は他のトランザクションによる読込みや更新ができなくなる。








コメントを残す